TT-Forge™
TT-Forgeは、TenstorrentのMLIRベースのコンパイラスタックで、モデルのコンパイル、さいてきか、デバッグ、かくちょうをおこなえます。
いまはパブリックベータとして、TT-Forgeをみなさんといっしょにつくれます。ほしいきのうをていあんしたり、プロトタイプをつくったり、バウンティをえたりできます。
イノベーションのためにデザイン
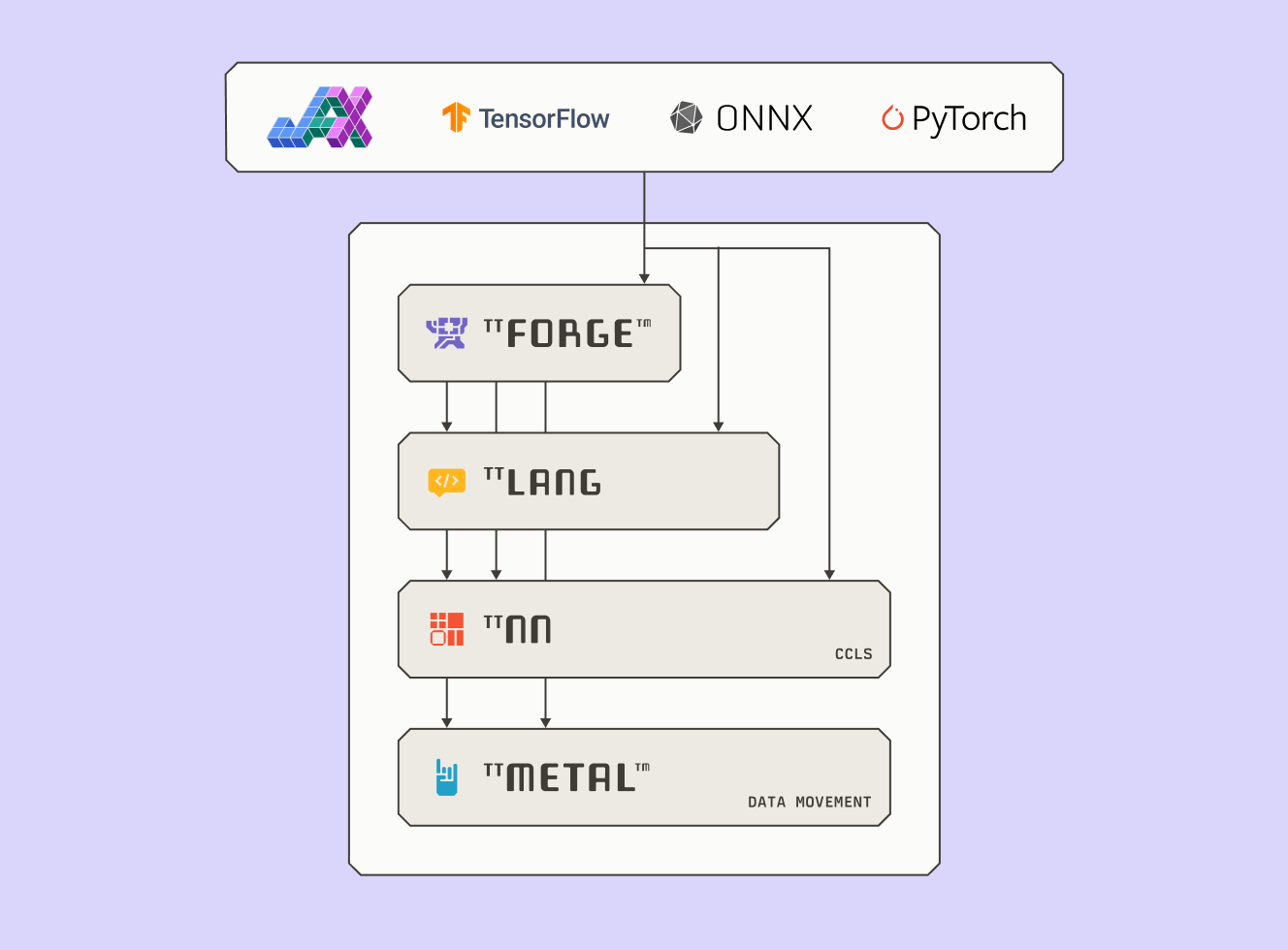
オープンソースのフレキシビリティのためにデザインされたTT-Forgeは、OpenXLA、MLIR、ONNX、TVM、PyTorch、TensorFlowとつながります。TT-Forgeは、カスタムシリコンでAIワークロードをおしすすめるためのモジュラーなきばんをていきょうします。モデルをさいてきかされたIRへとおろし、TenstorrentのローレベルAIハードウェアSDKであるTT-NNとTT-Metaliumでじっこうできるようにします。
なぜ MLIR?
MLIRはモジュラーで、かくちょうせいがあり、マルチレベルのちゅうしょうかをかのうにします。ふくすうのフレームワークにまたがり、カスタムdialectをサポートし、AIからHPCまであつかえます。MLIRのしなやかなデザインのおかげで、TT-Forgeはあたらしいops、フレームワーク、ハードウェアターゲットをすばやくとりこめます。MLIRエコシステムがひろがるのにあわせて、TT-Forgeもいっしょにしんかします。

どこからでもモデルをもってこられます* (ほぼ)
TT-XLA
マルチチッププロジェクトをJAXとPyTorchで
TT-XLAは、JAXとPyTorchのモデルをTenstorrentハードウェア向けにコンパイルしてじっこうするための、TenstorrentのPJRTベースのブリッジです。StableHLOをとおしたjust-in-time (JIT)コンパイルをサポートし、さいてきかされたじっこうのためにTT-MLIRへとわたします。
JAXでのネイティブサポートとPyTorch/XLAをとおしたとうごうにより、TT-XLAはTenstorrentハードウェアでモデルをじっこうできるようにコンパイルします。きそんコードへのへんこうはさいしょうげんで、マルチチップじっこうもサポートします。
TT-Forge-ONNX
シングルチッププロジェクトをONNXとTensorFlowで
TT-Forge-ONNXは、ディープラーニングモデルのけいさんグラフをさいてきかし、へんかんするためにデザインされた、Tenstorrentのフレームワークにいぞんしないフロントエンドです。TT-TVMをベースにしており、ONNX、TensorFlow、そのたのにたようなMLフレームワークのとりこみにたいおうし、モデルをTenstorrentハードウェアへこうりつよくもっていきやすくします。
とくちょう

パフォーマンス
さいてきかされたコンパイルとカスタムdialect (TTIR、TTNN、TTKernel) により、こうりつのよいじっこうがかのうになり、Tenstorrentハードウェアでのすいろんパフォーマンスをさいだいかします。tt-explorerによってパフォーマンスさいてきかもシンプルになります。

ハードウェアをりかいしたコンパイル
TT-Forge™は、ただモデルをコンパイルするだけではありません。どのハードウェアでうごくかをりかいしています。TTIRのようなカスタムdialectと、TT-MLIRをちゅうしんにくみたてられたコンパイラスタックにより、Tenstorrentのアーキテクチャにあわせてさいてきかされ、高いりようりつ、こうりつのよいメモリアクセス、そしてチップをまたぐスケーラブルなパフォーマンスをじつげんします。

ツール
Tenstorrentのツールチェーンは、TenstorrentハードウェアでのMLモデルのコンパイル、さいてきか、じっこうをシンプルにします。おもなツールには、TT-Blacksmith (すぐにうごくトレーニングれい)、TT-Explorer (モデルむけのビジュアルパフォーマンスアナライザ)、TT-NPE (network-on-chip (NoC) シミュレータおよびプロファイラ) があります。