最快的大上下文LLM推理
Tenstorrent Galaxy针对高端、延迟敏感的AI工作负载进行了优化。运行超级集群,支持代理工作流、实时系统和长上下文推理等高利润AI用例。利用相同的通用AI Tenstorrent系统进行解码和预填充。
首个Token时间减半,输出速度4倍
首个Token时间减半
在Blitz模式下,针对速度进行优化,Tenstorrent Galaxy超级集群在服务器间并行化预填充,高效地重叠数据放置和数据流,实现高利用率计算。
首个Token时间(秒), DeepSeek-R1-0528, 100k上下文
GPU
Tenstorrent
来源: Artificial Analysis; Nvidia前5名平均,包括Eigen AI、DeepInfra、Fireworks、Novita AI、Nebius等前5名提供商
4倍输出速度
Tenstorrent Galaxy超级集群上的解码智能地利用片上SRAM和DRAM在服务器间进行流水线处理,为代理工作负载提供最大上下文的大模型扩展。
输出速度(token/秒), DeepSeek-R1-0528, 100k上下文
GPU
Tenstorrent
来源: Artificial Analysis; Nvidia前5名平均,包括Eigen AI、DeepInfra、Fireworks、Novita AI、Nebius等前5名提供商
优势

快速
通过大量芯片的有效并行化,我们能够提供最快的大上下文LLM。

网络化AI
利用相同的硬件进行预填充和解码。网络化AI架构将计算、SRAM和DRAM内存以及网络统一为通用AI服务。

可扩展
为超级集群配置而设计。GPU架构受限于机箱,而Tenstorrent Galaxy突破了这一限制。

开放
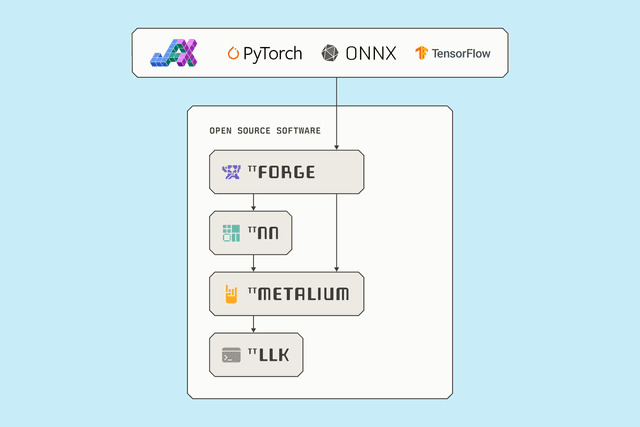
无需专有互联、交换机或HBM。完全开源的端到端软件栈。为您的AI解决方案部署最先进的模型。
技术
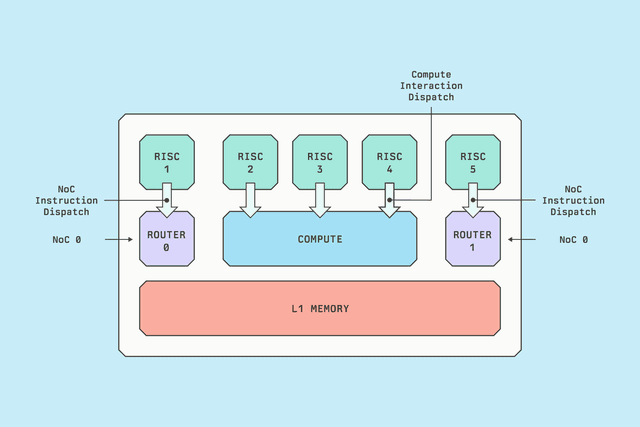
用于生产LLM推理的Blackhole架构

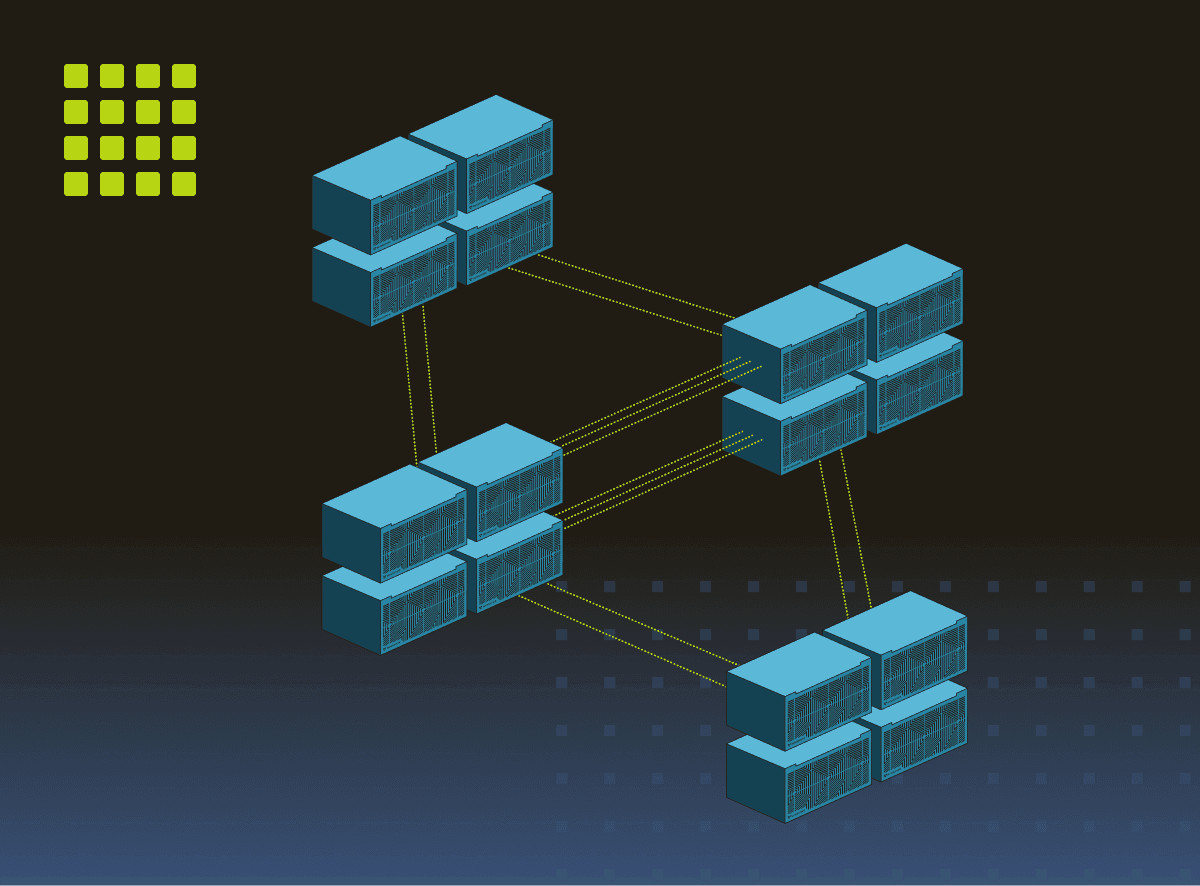
Tenstorrent Galaxy超级集群
运行任何东西 – 快速、经济、简单。高密度、可扩展的计算。添加系统,提升速度。
4 x Tenstorrent Galaxy™ Blackhole超级集群
Tenstorrent Galaxy™ Blackhole可以部署为超级集群,扩展为多服务器拓扑,可扩展到任意规模。4台Tenstorrent Galaxy™超级集群在大上下文LLM推理的性能和成本方面引领行业。