最速のラージコンテキストLLMインファレンス
Tenstorrent Galaxyは、プレミアムでレイテンシに敏感なAIワークロード向けに最適化されています。エージェントワークフロー、リアルタイムシステム、ロングコンテキスト推論などの高収益AIユースケースのためにスーパークラスターを稼働させましょう。デコードとプリフィルに同じ汎用AIのTenstorrentシステムを活用できます。
ファーストトークンまでの時間が半分、出力速度4倍
ファーストトークンまでの時間が半分
Blitzモードでは、速度に最適化し、Tenstorrent Galaxyスーパークラスターがサーバー間でプリフィルを並列化し、データ配置とデータフローを効率的にオーバーラップさせ、高稼働率のコンピュートを実現します。
ファーストトークンまでの時間(秒), DeepSeek-R1-0528, 100kコンテキスト
GPU
Tenstorrent
ソース: Artificial Analysis; Nvidiaトップ5平均 Eigen AI、DeepInfra、Fireworks、Novita AI、Nebiusを含むトップ5プロバイダー
4倍の出力速度
Tenstorrent Galaxyスーパークラスターでのデコードは、オンチップSRAMとDRAMをサーバー間でパイプライン化してインテリジェントに活用し、エージェントワークロード向けの最大コンテキストで大規模モデルのスケールアウトを可能にします。
出力速度(トークン/秒), DeepSeek-R1-0528, 100kコンテキスト
GPU
Tenstorrent
ソース: Artificial Analysis; Nvidiaトップ5平均 Eigen AI、DeepInfra、Fireworks、Novita AI、Nebiusを含むトップ5プロバイダー
メリット

高速
多数のチップにわたる効果的な並列化により、最速のラージコンテキストLLMを提供します。

ネットワークAI
プリフィルとデコードに同じハードウェアを活用。ネットワークAIアーキテクチャは、コンピュート、SRAMおよびDRAMメモリ、ネットワーキングを汎用AI向けに統合します。

スケーラブル
スーパークラスター構成でスケールするよう設計されています。GPUアーキテクチャは筐体に制約されますが、Tenstorrent Galaxyはそれを超えてスケールします。

オープン
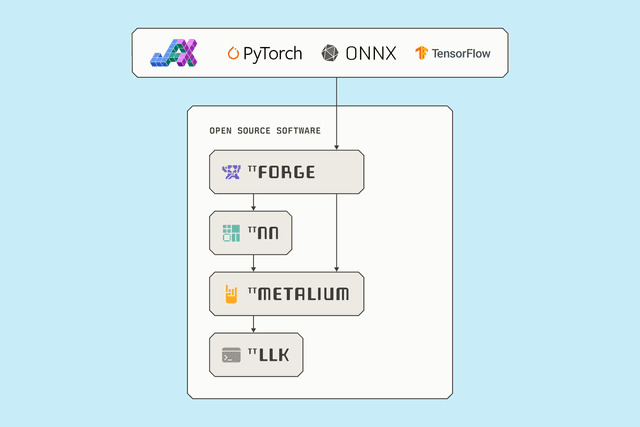
プロプライエタリなインターコネクト、スイッチ、HBMは不要。完全オープンソースのエンドツーエンドソフトウェアスタック。AIソリューション向けに最先端モデルをデプロイしましょう。
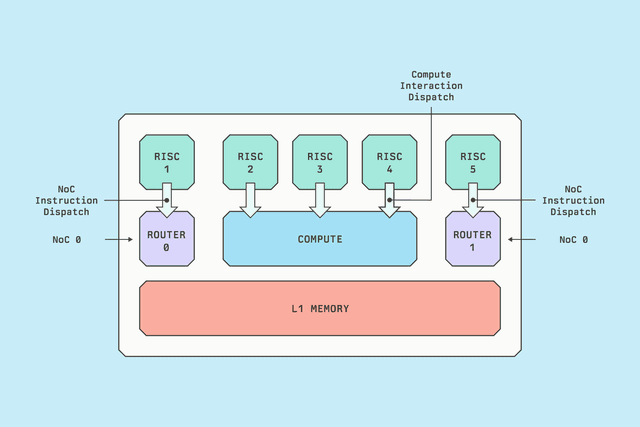
テクノロジー
プロダクションLLMインファレンス向けBlackholeアーキテクチャ

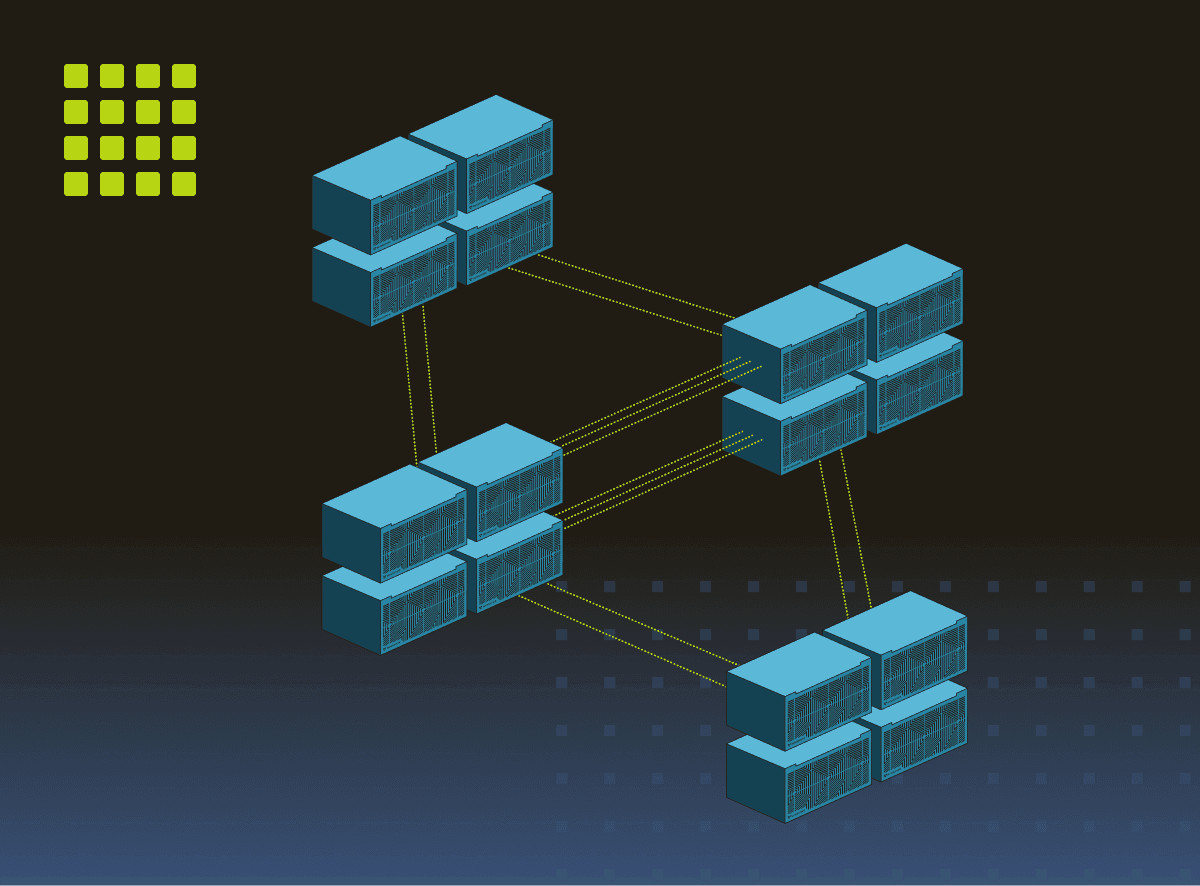
Tenstorrent Galaxyスーパークラスター
何でも実行 – 高速、手頃な価格、シンプル。高密度でスケーラブルなコンピュート。システムを追加すれば速度が向上。
4 x Tenstorrent Galaxy™ Blackholeスーパークラスター
Tenstorrent Galaxy™ Blackholeはスーパークラスターにデプロイでき、マルチサーバートポロジーに拡張して任意のサイズにスケールアウトできます。4台のTenstorrent Galaxy™スーパークラスターが、ラージコンテキストLLMインファレンスの性能とコストで業界をリードします。