가장 빠른 대규모 컨텍스트 LLM 추론
Tenstorrent Galaxy는 프리미엄 저지연 AI 워크로드에 최적화되어 있습니다. 에이전트 워크플로우, 실시간 시스템, 롱 컨텍스트 추론 등 고수익 AI 사용 사례를 위한 슈퍼클러스터를 운영하세요. 디코드와 프리필에 동일한 범용 AI Tenstorrent 시스템을 활용할 수 있습니다.
첫 토큰까지의 시간 절반, 출력 속도 4배
첫 토큰까지의 시간 절반
Blitz 모드에서는 속도에 최적화하여 Tenstorrent Galaxy 슈퍼클러스터가 서버 간 프리필을 병렬화하고, 데이터 배치와 데이터 플로우를 효율적으로 오버랩하며, 높은 활용률의 컴퓨팅을 실현합니다.
첫 토큰까지의 시간(초), DeepSeek-R1-0528, 100k 컨텍스트
GPU
Tenstorrent
출처: Artificial Analysis; Nvidia 상위 5개 평균 Eigen AI, DeepInfra, Fireworks, Novita AI, Nebius를 포함한 상위 5개 프로바이더
4배 출력 속도
Tenstorrent Galaxy 슈퍼클러스터에서의 디코드는 온칩 SRAM과 DRAM을 서버 간 파이프라인화하여 인텔리전트하게 활용하며, 에이전트 워크로드를 위한 가장 큰 컨텍스트로 대규모 모델의 스케일 아웃을 가능하게 합니다.
출력 속도(토큰/초), DeepSeek-R1-0528, 100k 컨텍스트
GPU
Tenstorrent
출처: Artificial Analysis; Nvidia 상위 5개 평균 Eigen AI, DeepInfra, Fireworks, Novita AI, Nebius를 포함한 상위 5개 프로바이더
장점

빠름
많은 칩에 걸친 효과적인 병렬화를 통해 가장 빠른 대규모 컨텍스트 LLM을 제공합니다.

네트워크 AI
프리필과 디코드에 동일한 하드웨어를 활용합니다. 네트워크 AI 아키텍처는 컴퓨팅, SRAM 및 DRAM 메모리, 네트워킹을 범용 AI를 위해 통합합니다.

확장 가능
슈퍼클러스터 구성으로 확장할 수 있도록 설계되었습니다. GPU 아키텍처는 박스에 제한되지만 Tenstorrent Galaxy는 그것을 넘어 확장합니다.

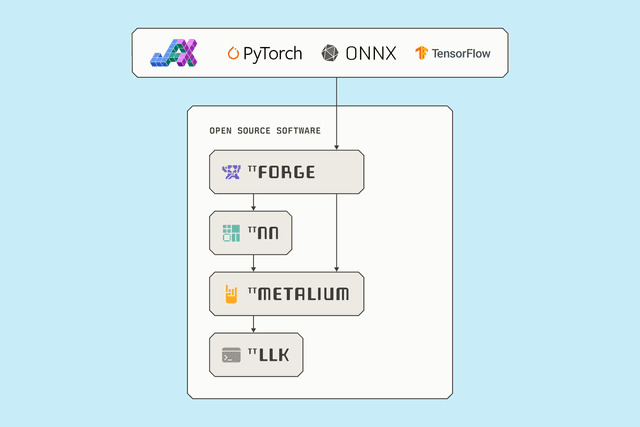
개방형
독점 인터커넥트, 스위치 또는 HBM이 필요 없습니다. 완전한 오픈소스 엔드투엔드 소프트웨어 스택. AI 솔루션을 위한 최첨단 모델을 배포하세요.
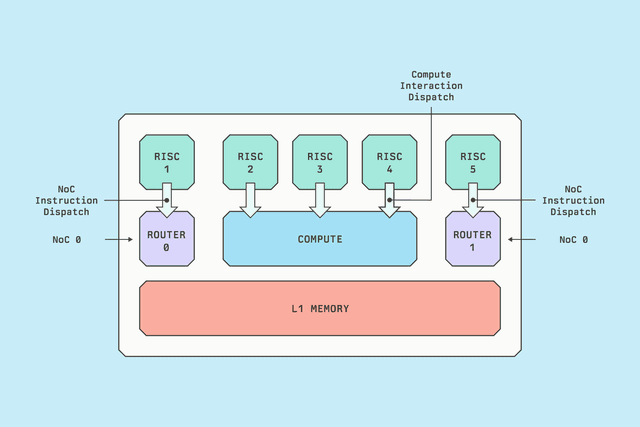
기술
프로덕션 LLM 추론을 위한 Blackhole 아키텍처

Tenstorrent Galaxy 슈퍼클러스터
모든 것을 실행 – 빠르고, 저렴하고, 간단합니다. 고밀도의 확장 가능한 컴퓨팅. 시스템을 추가하면 속도가 향상됩니다.
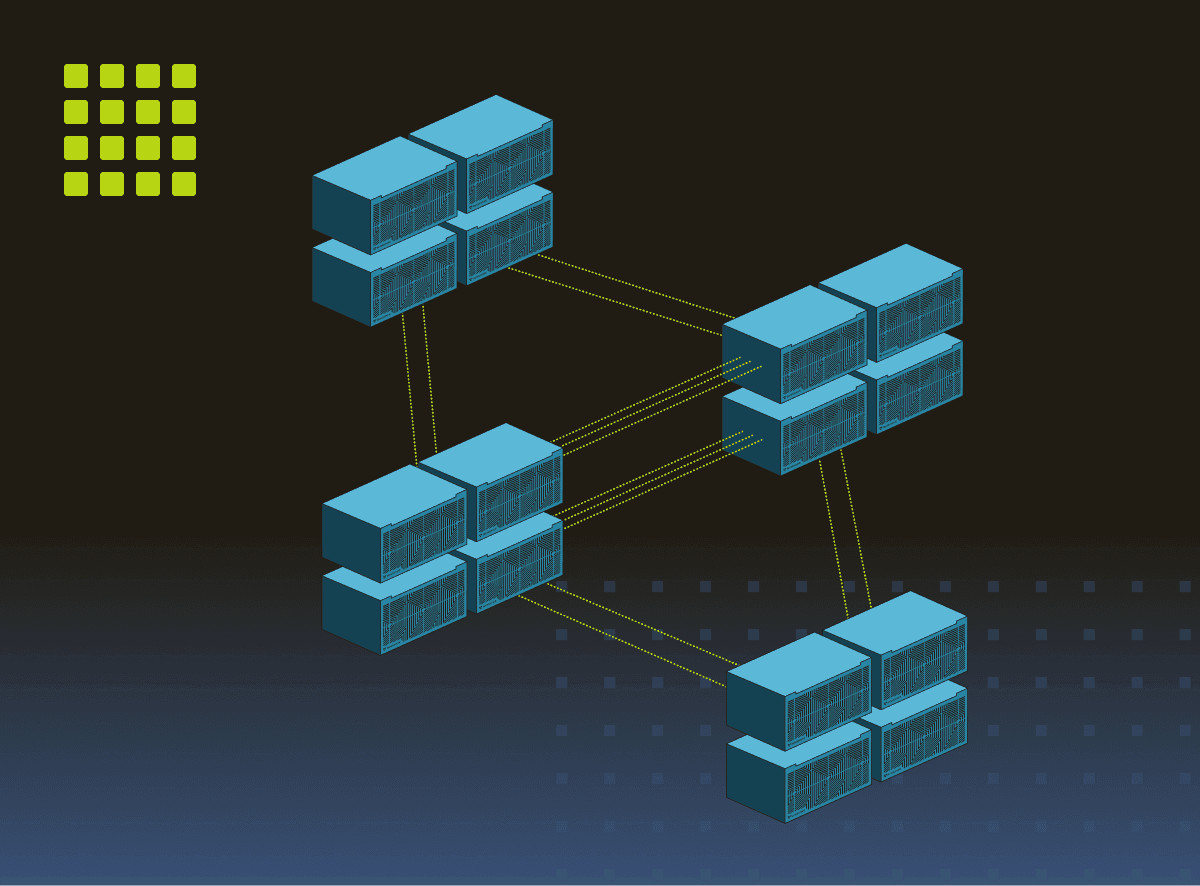
4 x Tenstorrent Galaxy™ Blackhole 슈퍼클러스터
Tenstorrent Galaxy™ Blackhole는 슈퍼클러스터로 배포할 수 있으며, 멀티 서버 토폴로지로 확장하여 어떤 규모로든 스케일 아웃할 수 있습니다. 4대의 Tenstorrent Galaxy™ 슈퍼클러스터가 대규모 컨텍스트 LLM 추론의 성능과 비용에서 업계를 선도합니다.