TT-Forge™
TT-Forge 是 Tenstorrent 基于 MLIR 的编译器栈,可让你编译、优化、调试并扩展模型。
TT-Forge 现已进入公开测试阶段,由你共同塑造。你可以提出功能建议、制作原型,或领取赏金任务。
为创新而打造
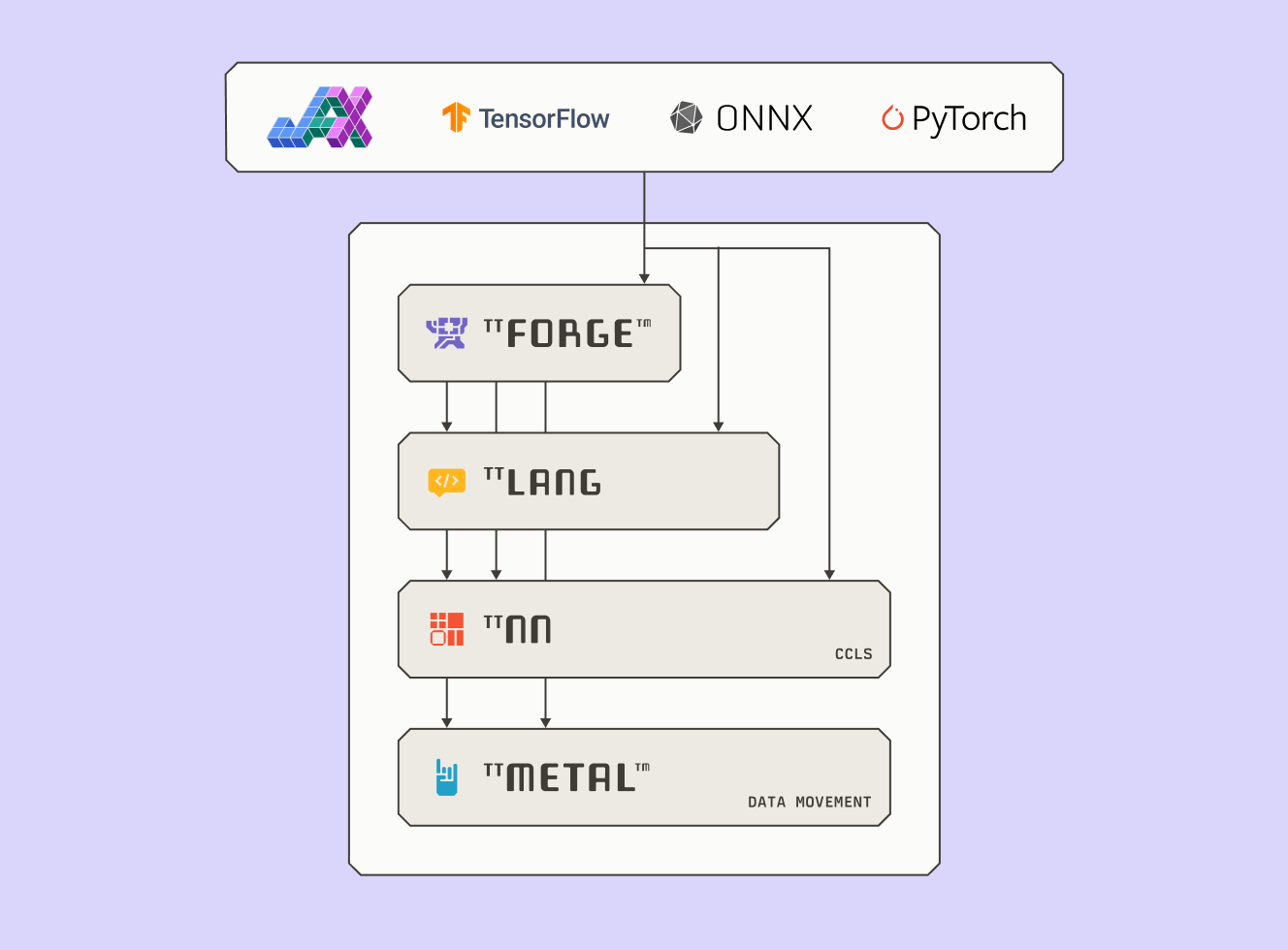
TT-Forge 专为开源灵活性而设计,可与 OpenXLA、MLIR、ONNX、TVM、PyTorch 和 TensorFlow 连接。TT-Forge 为在定制硅片上推进 AI 工作负载提供了模块化基础。它将模型下沉为优化后的 IR,以便在 TT-NN 和 TT-Metalium 上执行;后者是 Tenstorrent 的底层 AI 硬件 SDK。
为什么选择 MLIR?
MLIR 具有模块化、可扩展,并支持多层级抽象。它跨越多个框架,支持自定义 dialect,并可处理从 AI 到 HPC 的各种工作负载。凭借 MLIR 的灵活设计,TT-Forge 能够快速采用新的 ops、框架和硬件目标。随着 MLIR 生态不断扩展,TT-Forge 也会同步演进。

几乎可从任何地方导入你的模型*
TT-XLA
面向 JAX 和 PyTorch 的多芯片项目
TT-XLA 是 Tenstorrent 基于 PJRT 的桥接层,用于在 Tenstorrent 硬件上编译并运行来自 JAX 和 PyTorch 的模型。它支持通过 StableHLO 进行 just-in-time (JIT) 编译,并将结果送入 TT-MLIR 以实现优化执行。
借助 JAX 的原生支持以及通过 PyTorch/XLA 的集成,TT-XLA 可将模型编译为在 Tenstorrent 硬件上运行,仅需对现有代码做极少修改,并支持多芯片执行。
TT-Forge-ONNX
面向 ONNX 和 TensorFlow 的单芯片项目
TT-Forge-ONNX 是 Tenstorrent 的框架无关前端,旨在优化并转换深度学习模型的计算图。它由 TT-TVM 提供支持,可接收 ONNX、TensorFlow 以及类似的 ML 框架,使你更容易高效地将模型带到 Tenstorrent 硬件上。
功能

性能
优化后的编译和自定义 dialect(TTIR、TTNN、TTKernel)可实现高效执行,最大化 Tenstorrent 硬件上的推理性能。借助 tt-explorer,性能优化也得以简化。

硬件感知编译
TT-Forge™ 不只是编译模型——它还理解模型所运行的硬件。借助 TTIR 等自定义 dialect,以及围绕 TT-MLIR 构建的编译器栈,它针对 Tenstorrent 的架构进行了优化,从而实现高利用率、高效内存访问,以及跨芯片的可扩展性能。

工具
Tenstorrent 的工具链简化了在 Tenstorrent 硬件上对 ML 模型进行编译、优化和执行的流程。关键工具包括:TT-Blacksmith(可直接运行的训练示例)、TT-Explorer(模型的可视化性能分析器)以及 TT-NPE(network-on-chip (NoC) 模拟器和分析器)。