Machine Learning
White Paper
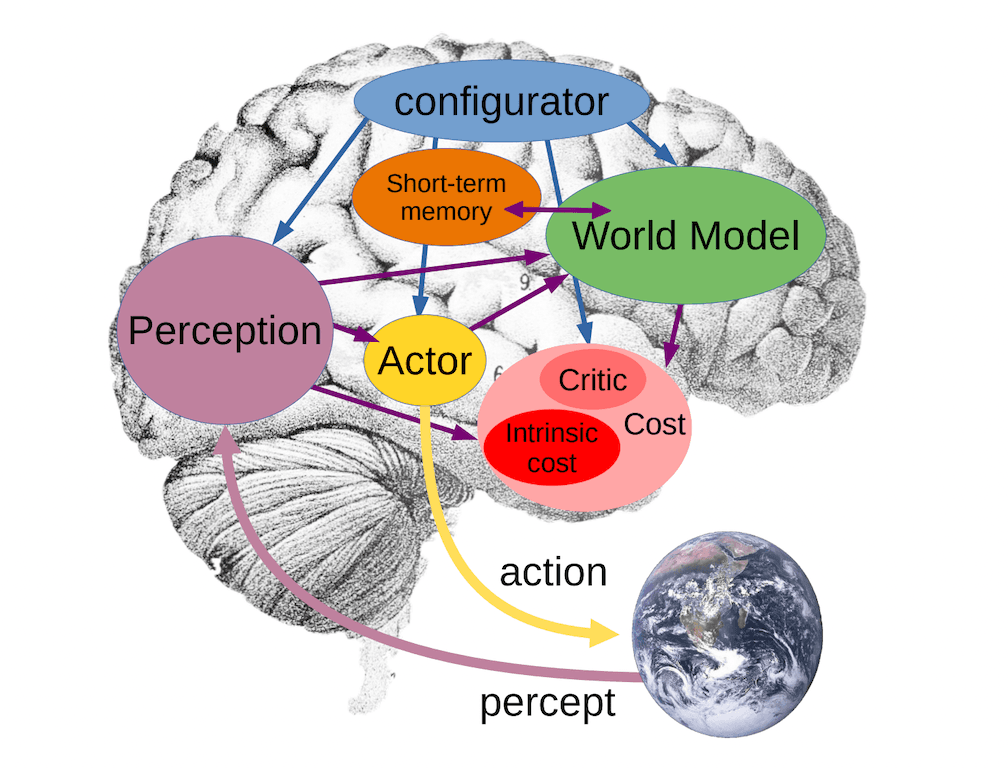
A Path Towards Autonomous Machine Intelligence
Feb 2, 2024
Machine Learning
Software
White Paper
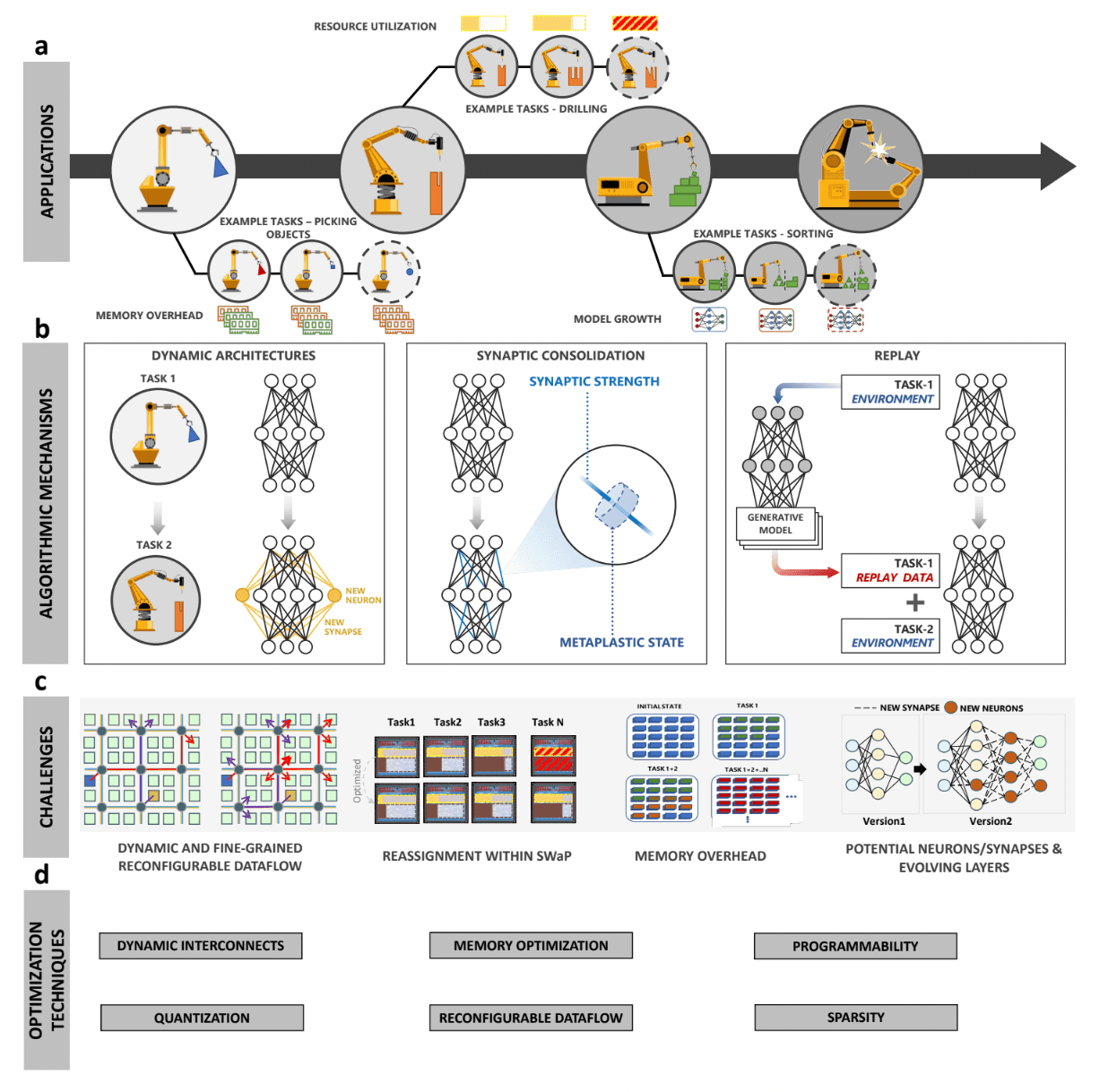
Design Principles for Lifelong Learning AI Accelerators
Aug 16, 2023

Machine Learning
White Paper
A Review of Sparse Expert Models in Deep Learning
May 9, 2023
Machine Learning
White Paper
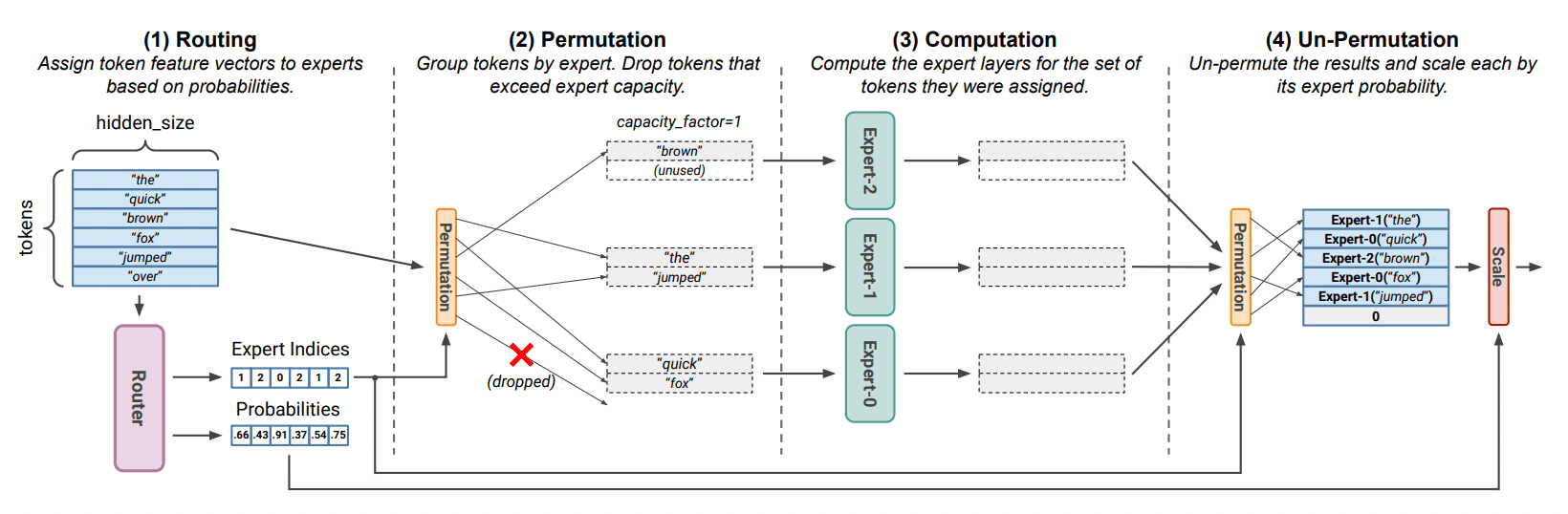
MegaBlocks: Efficient Sparse Training with Mixture-of-Experts
Mar 20, 2023
Machine Learning
White Paper
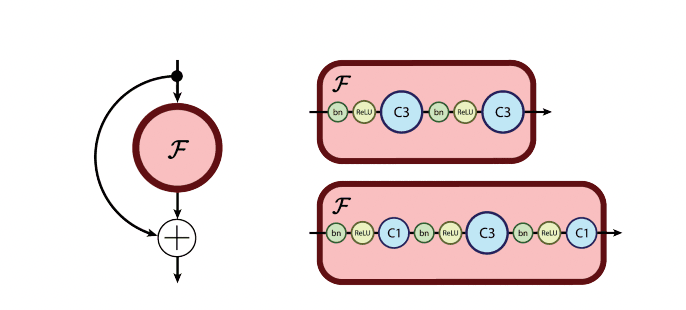
The Reversible Residual Network: Backpropagation Without Storing Activations
Mar 3, 2023
Machine Learning
White Paper
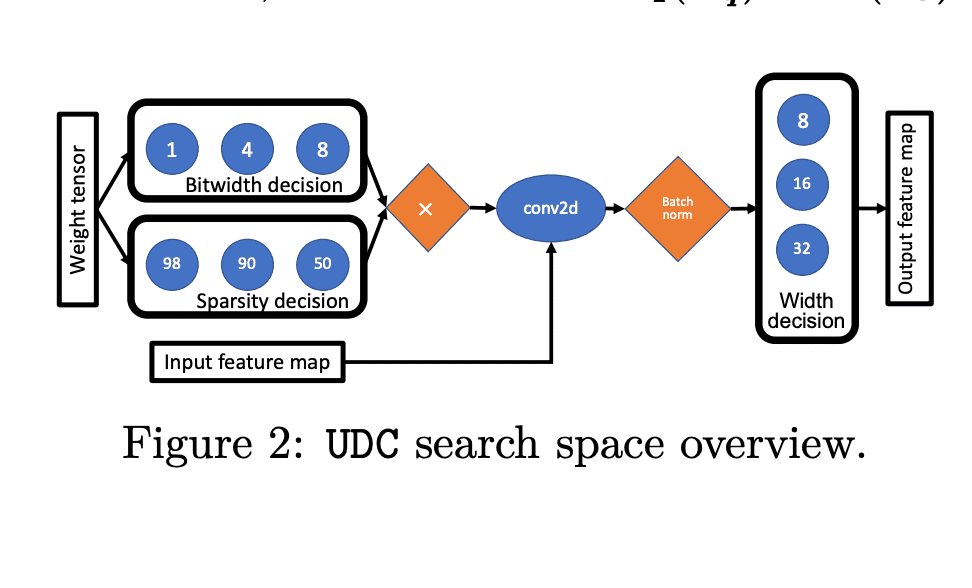
UDC: Unified DNAS for Compressible TinyML Models for Neural Processing Units
Feb 10, 2023
Machine Learning
White Paper
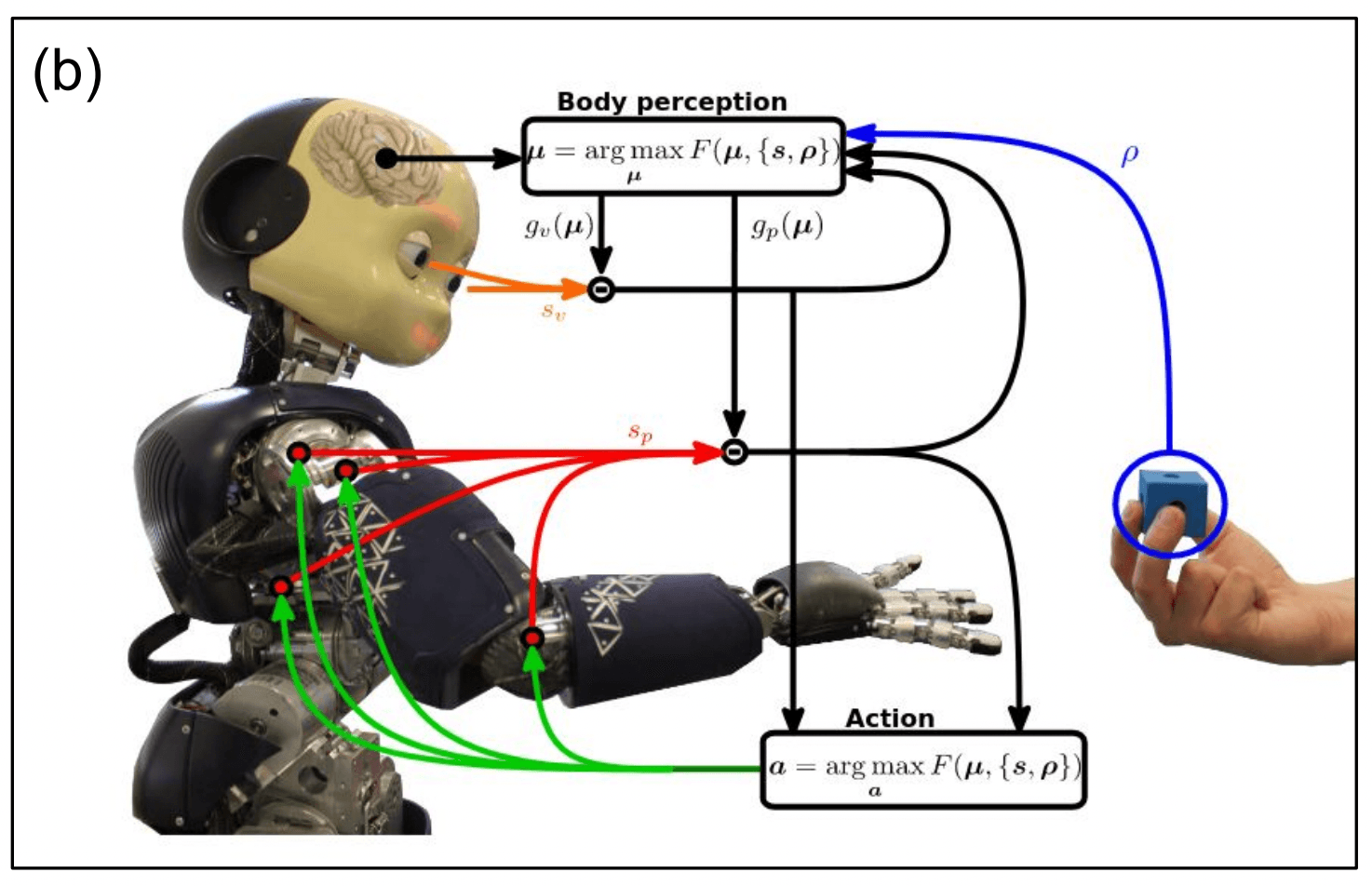
Predictive Coding Towards a Future of Deep Learning Beyond Backpropagation
Jan 25, 2023

Machine Learning
White Paper
Reversible Architectures for Arbitrarily Deep Residual Neural Networks
Jan 18, 2023
Machine Learning
Research
White Paper
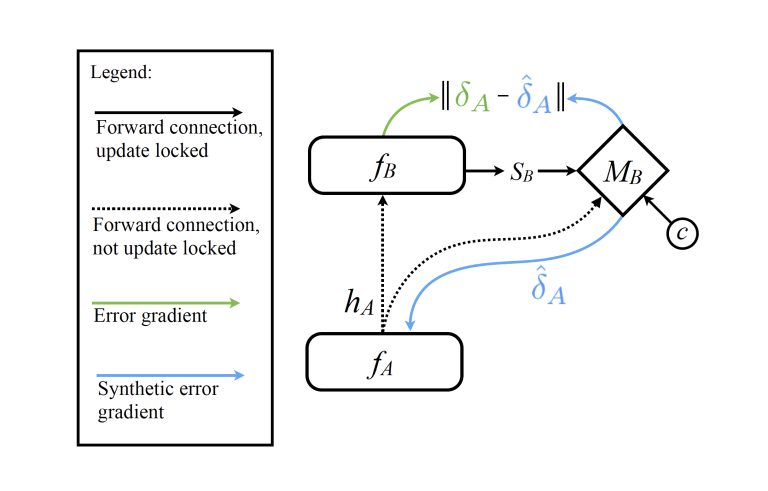
Decoupled Neural Interfaces using Synthetic Gradients
Jan 10, 2023

White Paper
Attention Is All You Need
May 10, 2021